



2025-06-30
Artwork by @allison_horst
| Energy market liberalization created complex, interconnected trading systems | |
| Renewable energy transition introduces uncertainty and volatility from weather-dependent generation | |
| Traditional point forecasts are inadequate for modern energy markets with increasing uncertainty | |
| Risk inherently is a probabilistic concept | |
| Probabilistic forecasting essential for risk management, planning and decision making in volatile energy environments | |
| Online learning methods needed for fast-updating models with streaming energy data |


Reduces estimation time by 2-3 orders of magnitude
Maintainins competitive forecasting accuracy
Real-World Validation in Energy Markets
Predict high-resolution electricity peaks using only low-resolution data
Combine GAMs and DNN’s for superior accuracy
Won Western Power Distribution Competition
Won Best-Student-Presentation Award

The Idea:
Combine multiple forecasts instead of choosing one
Combination weights may vary over time, over the distribution or both
2 Popular options for combining distributions:
Simple Example:
\[\begin{align} Y_t & \sim \mathcal{N}(0,\,1) \\ \widehat{X}_{t,1} & \sim \widehat{F}_{1} = \mathcal{N}(-1,\,1) \\ \widehat{X}_{t,2} & \sim \widehat{F}_{2} = \mathcal{N}(3,\,4) \label{eq:dgp_sim1} \end{align}\]
Penalized cubic B-Splines for smoothing weights:
Let \(\varphi=(\varphi_1,\ldots, \varphi_L)\) be bounded basis functions on \((0,1)\) Then we approximate \(w_{t,k}\) by
\[\begin{align} w_{t,k}^{\text{smooth}} = \sum_{l=1}^L \beta_l \varphi_l = \beta'\varphi \end{align}\]
with parameter vector \(\beta\). The latter is estimated to penalize \(L_2\)-smoothing which minimizes
\[\begin{equation} \| w_{t,k} - \beta' \varphi \|^2_2 + \lambda \| \mathcal{D}^{d} (\beta' \varphi) \|^2_2 \label{eq_function_smooth} \end{equation}\]
with differential operator \(\mathcal{D}\)
Computation is easy, since we have an analytical solution
We receive the constant solution for high values of \(\lambda\) when setting \(d=1\)
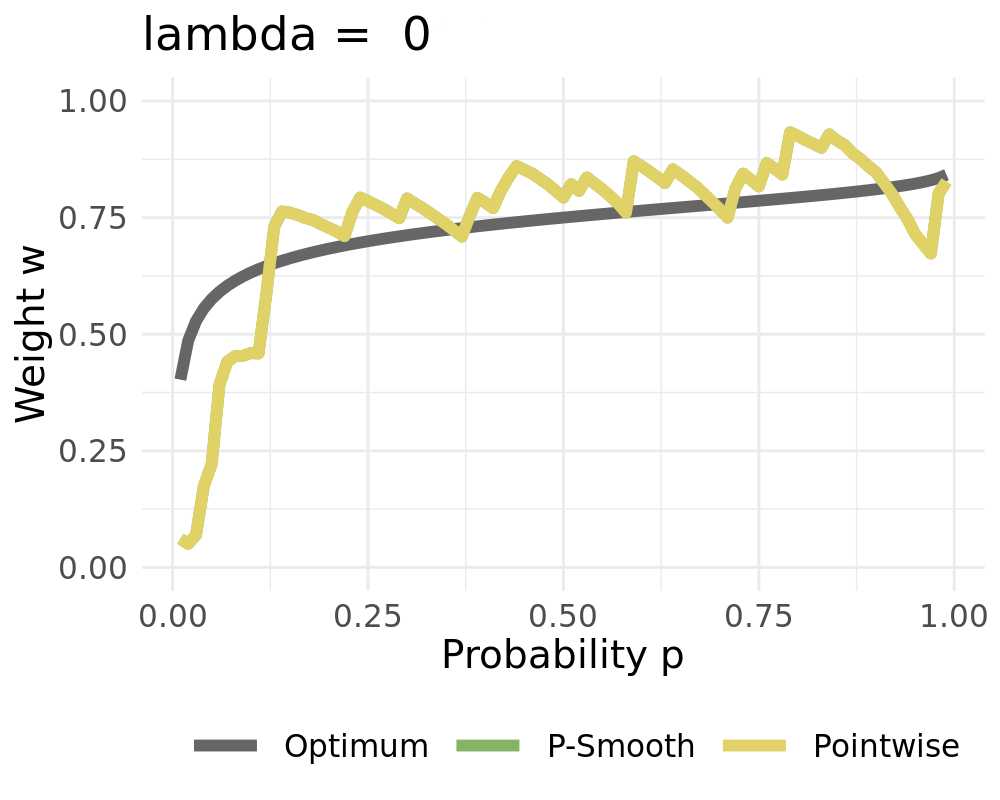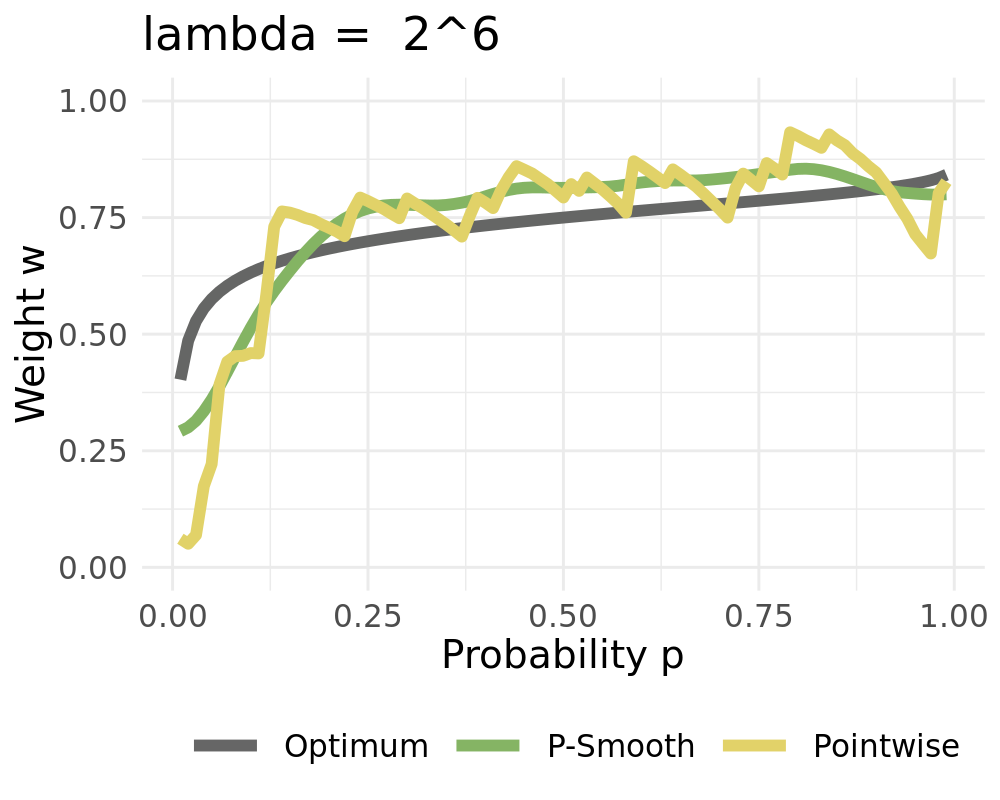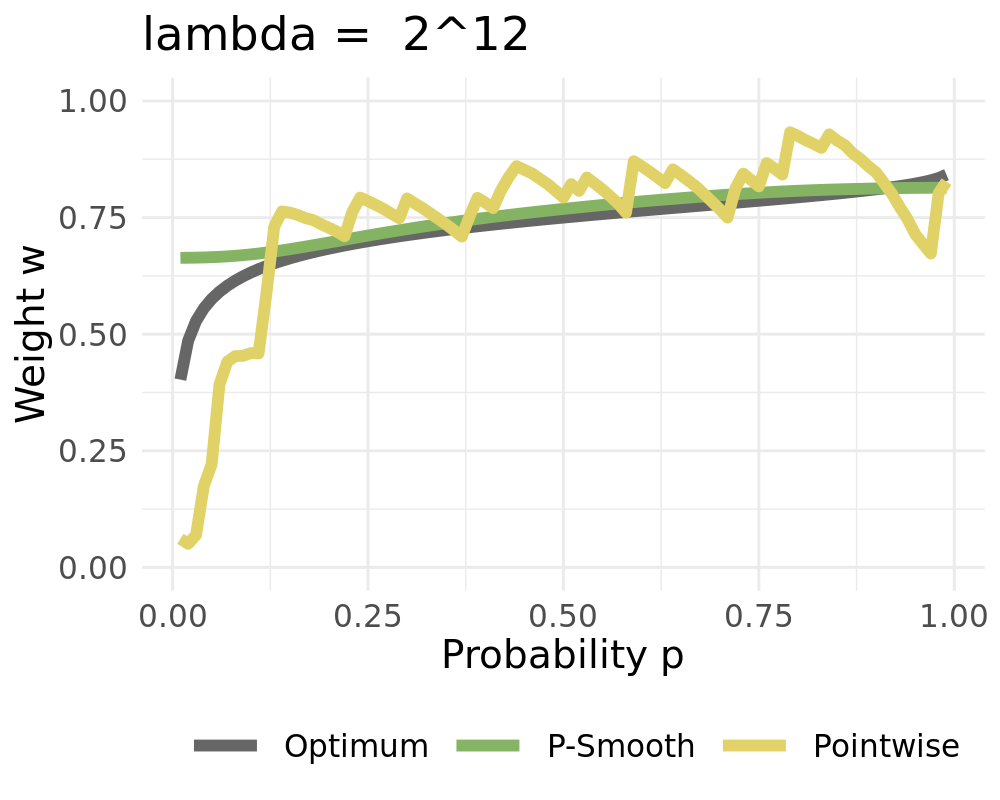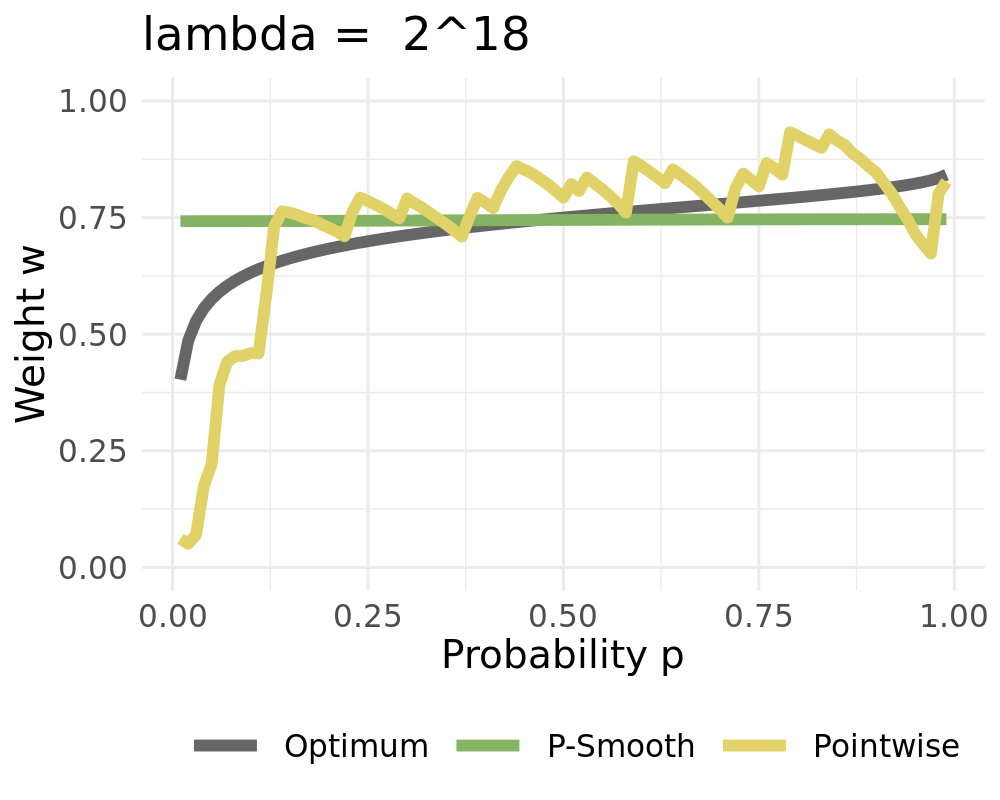
Represent weights as linear combinations of bounded basis functions:
\[\begin{equation} w_{t,k} = \sum_{l=1}^L \beta_{t,k,l} \varphi_l = \boldsymbol \beta_{t,k}' \boldsymbol \varphi \end{equation}\]
A popular choice are are B-Splines as local basis functions
\(\boldsymbol \beta_{t,k}\) is calculated using a reduced regret matrix:
\[\begin{equation} \underbrace{\boldsymbol r_{t}}_{\text{LxK}} = \frac{L}{P} \underbrace{\boldsymbol B'}_{\text{LxP}} \underbrace{\left({\boldsymbol{QL}}_{\mathcal{P}}^{\nabla}(\widetilde{\boldsymbol X}_{t},Y_t)- {\boldsymbol{QL}}_{\mathcal{P}}^{\nabla}(\widehat{\boldsymbol X}_{t},Y_t)\right)}_{\text{PxK}} \end{equation}\]
\(\boldsymbol r_{t}\) is transformed from PxK to LxK
If \(L = P\) it holds that \(\boldsymbol \varphi = \boldsymbol{I}\) For \(L = 1\) we receive constant weights
Weights converge to the constant solution if \(L\rightarrow 1\)
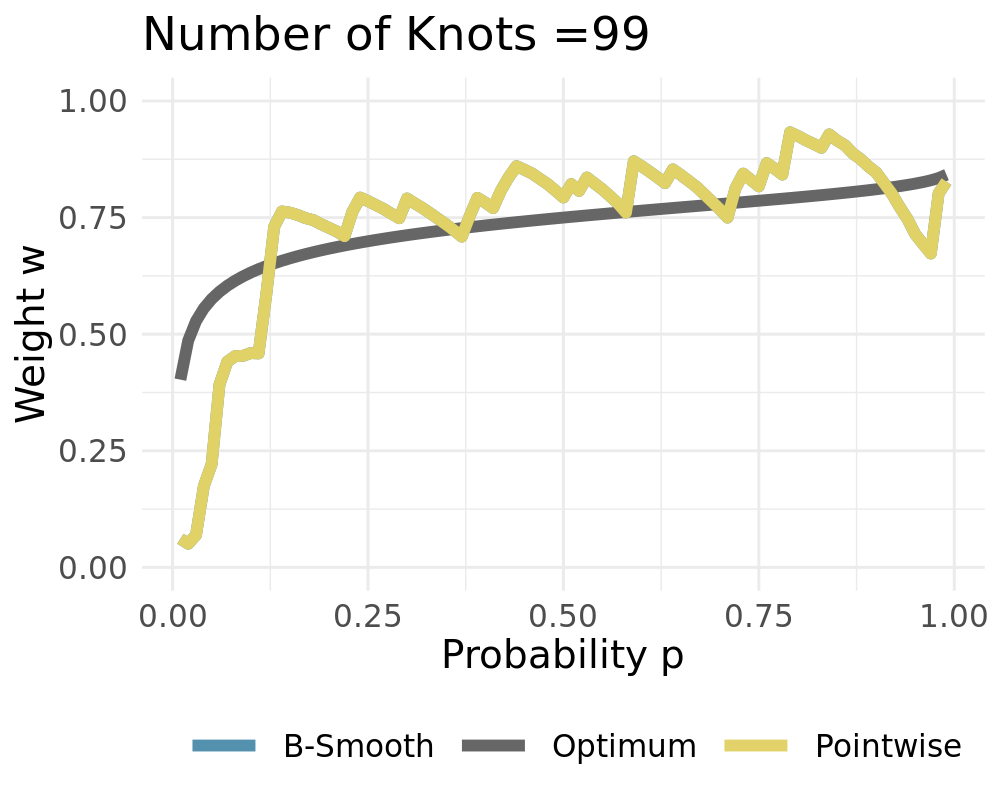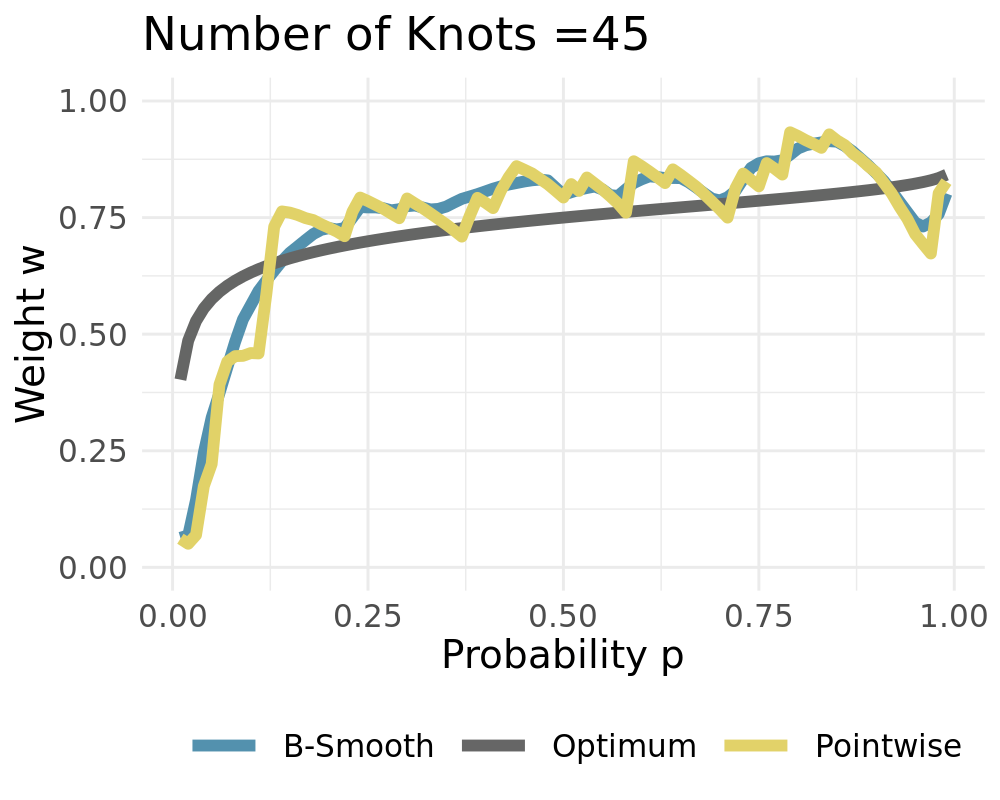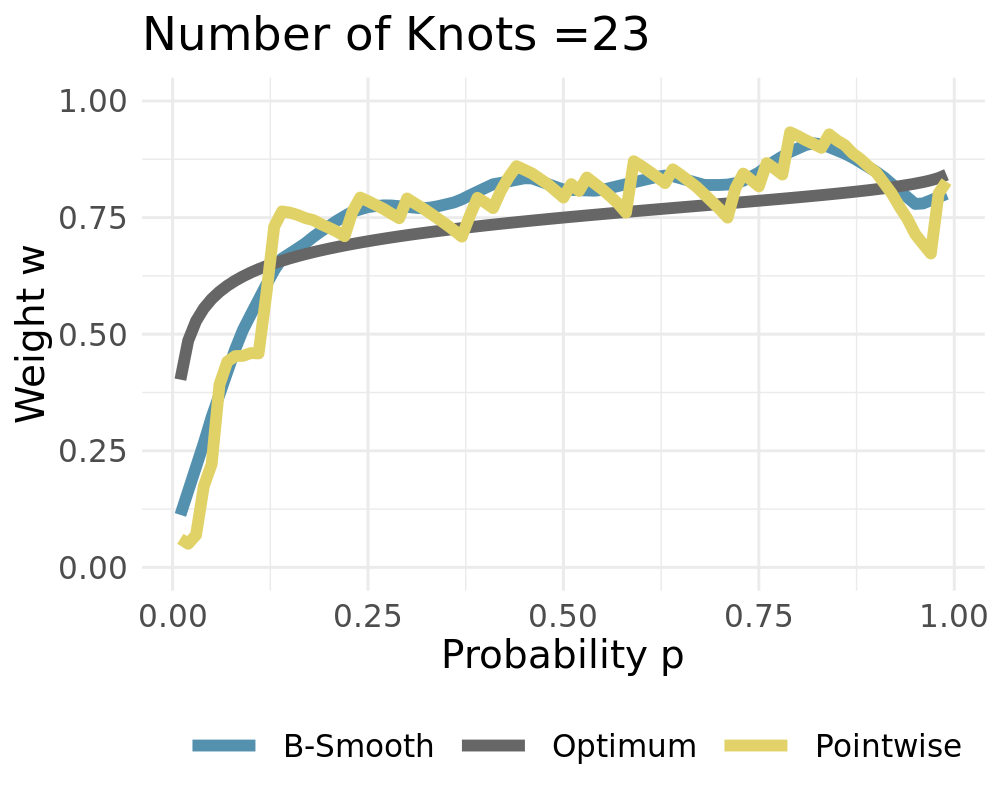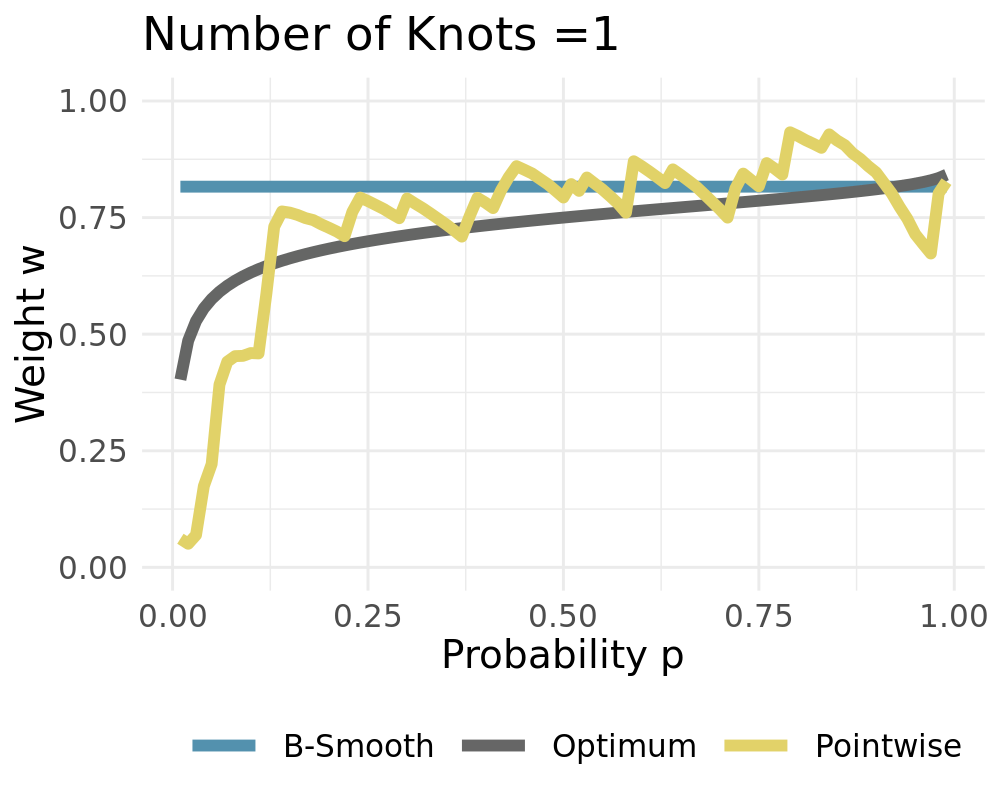
Data Generating Process of the simple probabilistic example:
\[\begin{align*} Y_t &\sim \mathcal{N}(0,\,1)\\ \widehat{X}_{t,1} &\sim \widehat{F}_{1}=\mathcal{N}(-1,\,1) \\ \widehat{X}_{t,2} &\sim \widehat{F}_{2}=\mathcal{N}(3,\,4) \end{align*}\]
Deviation from best attainable QL (1000 runs).

CRPS Values for different \(\lambda\) (1000 runs)

CRPS for different number of knots (1000 runs)

The same simulation carried out for different algorithms (1000 runs):
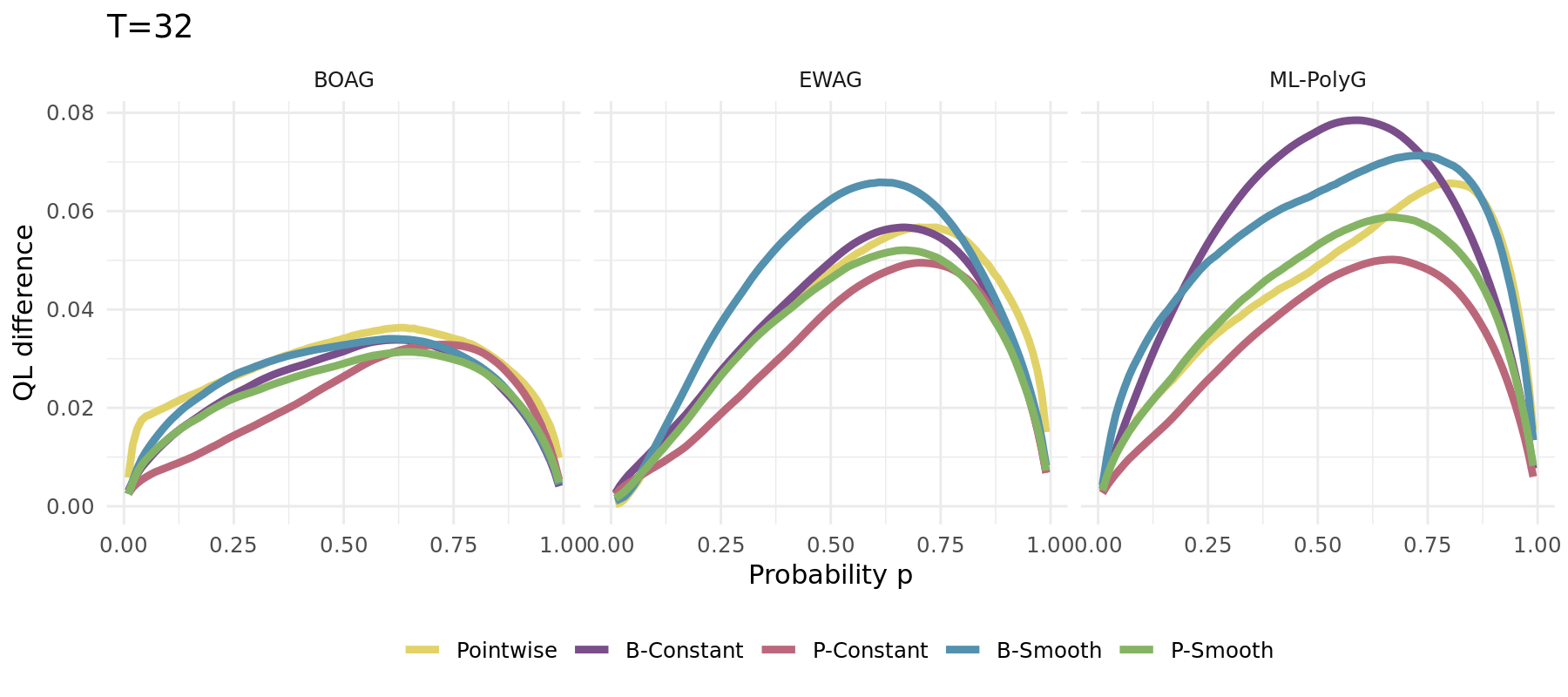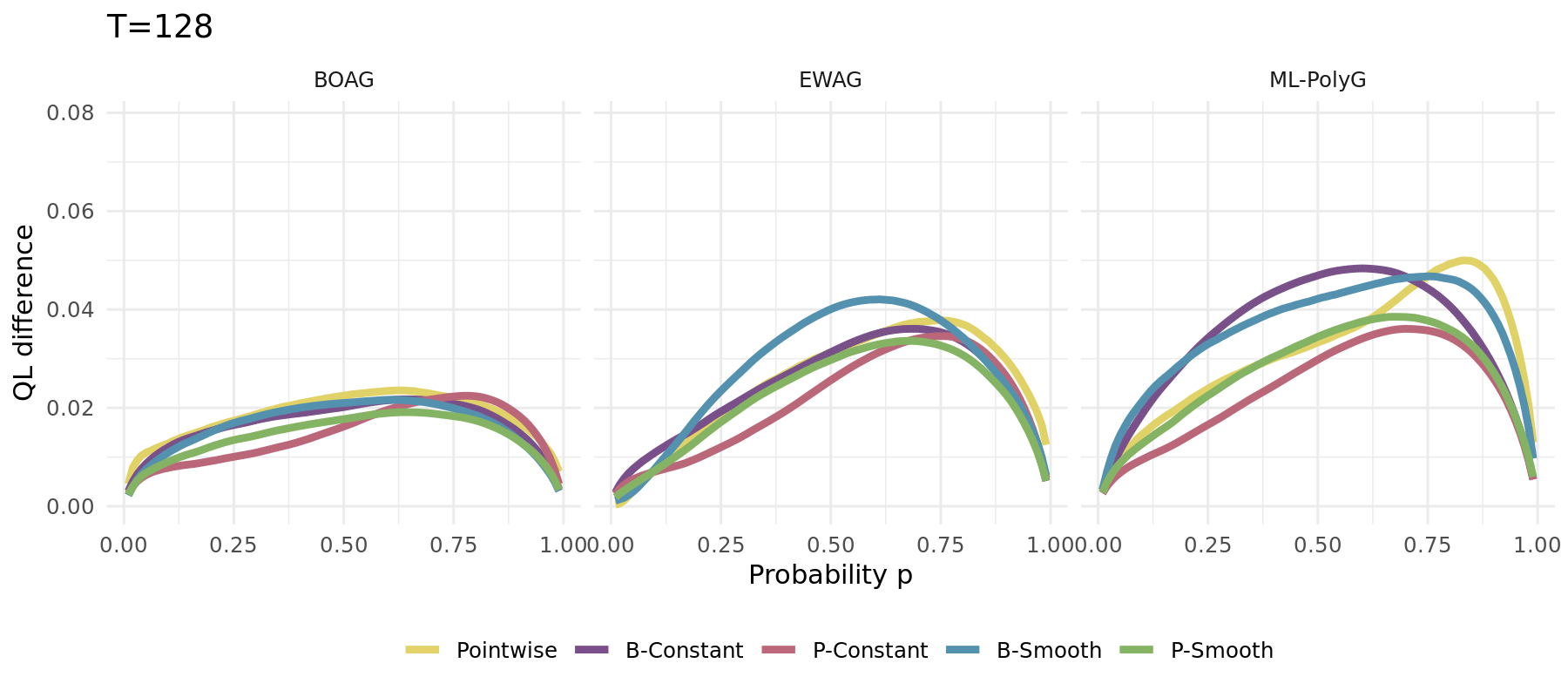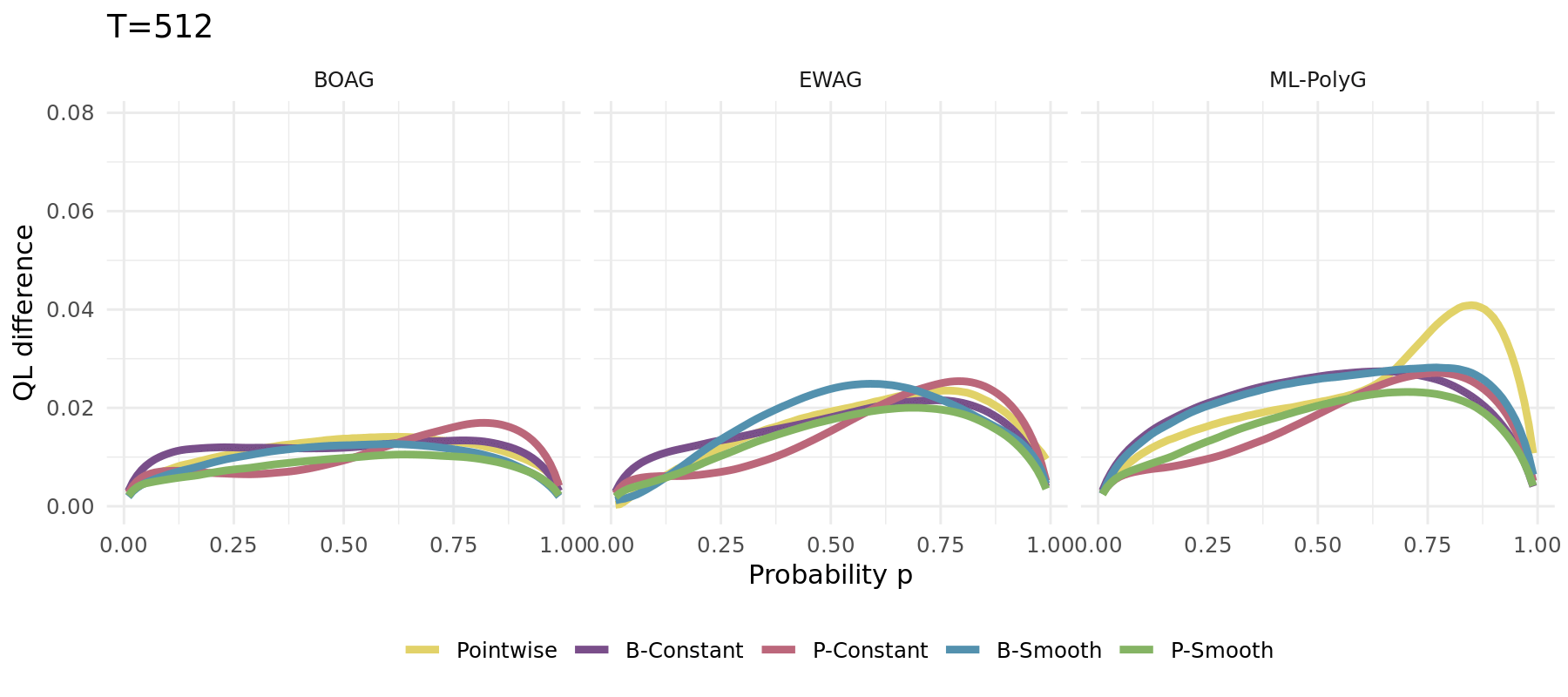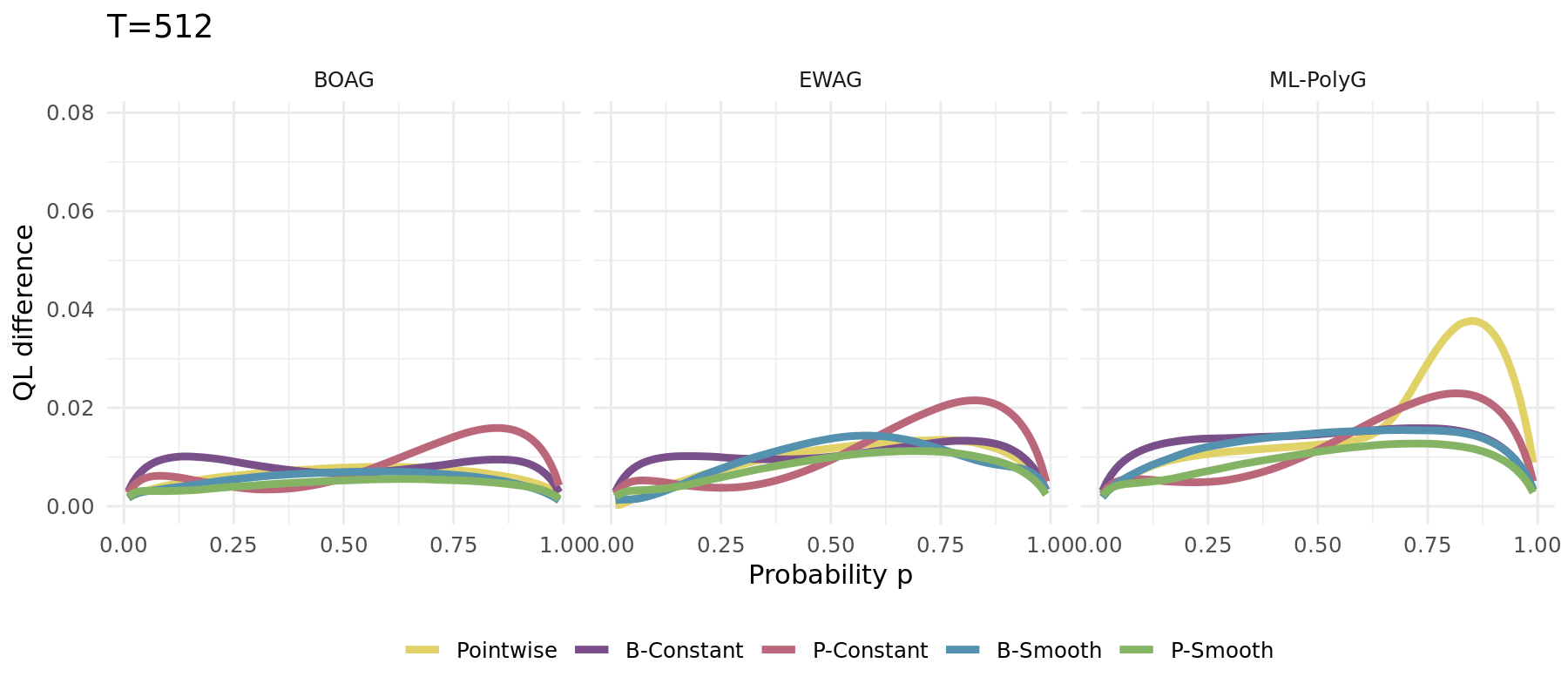
\[\begin{align*} Y_t &\sim \mathcal{N}\left(\frac{\sin(0.005 \pi t )}{2},\,1\right) \\ \widehat{X}_{t,1} &\sim \widehat{F}_{1} = \mathcal{N}(-1,\,1) \\ \widehat{X}_{t,2} &\sim \widehat{F}_{2} = \mathcal{N}(3,\,4) \end{align*}\]
Changing optimal weights
Single run example depicted aside
No forgetting leads to long-term constant weights


Data:
Combination methods:
Tuning paramter grids:

Simple exponential smoothing with additive errors (ETS-ANN):
\[\begin{align*} Y_{t} = l_{t-1} + \varepsilon_t \quad \text{with} \quad l_t = l_{t-1} + \alpha \varepsilon_t \quad \text{and} \quad \varepsilon_t \sim \mathcal{N}(0,\sigma^2) \end{align*}\]
Quantile regression (QuantReg): For each \(p \in \mathcal{P}\) we assume:
\[\begin{align*} F^{-1}_{Y_t}(p) = \beta_{p,0} + \beta_{p,1} Y_{t-1} + \beta_{p,2} |Y_{t-1}-Y_{t-2}| \end{align*}\]
ARIMA(1,0,1)-GARCH(1,1) with Gaussian errors (ARMA-GARCH):
\[\begin{align*} Y_{t} = \mu + \phi(Y_{t-1}-\mu) + \theta \varepsilon_{t-1} + \varepsilon_t \quad \text{with} \quad \varepsilon_t = \sigma_t Z, \quad \sigma_t^2 = \omega + \alpha \varepsilon_{t-1}^2 + \beta \sigma_{t-1}^2 \quad \text{and} \quad Z_t \sim \mathcal{N}(0,1) \end{align*}\]
ARIMA(0,1,0)-I-EGARCH(1,1) with Gaussian errors (I-EGARCH):
\[\begin{align*} Y_{t} = \mu + Y_{t-1} + \varepsilon_t \quad \text{with} \quad \varepsilon_t = \sigma_t Z, \quad \log(\sigma_t^2) = \omega + \alpha Z_{t-1}+ \gamma (|Z_{t-1}|-\mathbb{E}|Z_{t-1}|) + \beta \log(\sigma_{t-1}^2) \quad \text{and} \quad Z_t \sim \mathcal{N}(0,1) \end{align*}\]
ARIMA(0,1,0)-GARCH(1,1) with student-t errors (I-GARCHt):
\[\begin{align*} Y_{t} = \mu + Y_{t-1} + \varepsilon_t \quad \text{with} \quad \varepsilon_t = \sigma_t Z, \quad \sigma_t^2 = \omega + \alpha \varepsilon_{t-1}^2 + \beta \sigma_{t-1}^2 \quad \text{and} \quad Z_t \sim t(0,1, \nu) \end{align*}\]
| ETS | QuantReg | ARMA-GARCH | I-EGARCH | I-GARCHt |
|---|---|---|---|---|
| 2.101(>.999) | 1.358(>.999) | 0.52(0.993) | 0.511(0.999) | -0.037(0.406) |
| BOAG | EWAG | ML-PolyG | BMA | QRlin | QRconv | |
|---|---|---|---|---|---|---|
| Pointwise | -0.170(0.055) | -0.089(0.175) | -0.141(0.112) | 0.032(0.771) | 3.482(>.999) | -0.019(0.309) |
| B-Constant | -0.118(0.146) | -0.049(0.305) | -0.090(0.218) | 0.038(0.834) | 4.002(>.999) | 0.539(0.996) |
| P-Constant | -0.138(0.020) | -0.070(0.137) | -0.133(0.026) | 0.039(0.851) | 5.275(>.999) | 0.009(0.683) |
| B-Smooth | -0.173(0.062) | -0.065(0.276) | -0.141(0.118) | -0.042(0.386) | - | - |
| P-Smooth | -0.182(0.039) | -0.107(0.121) | -0.160(0.065) | 0.040(0.804) | 3.495(>.999) | -0.012(0.369) |
CRPS difference to Naive. Negative values correspond to better performance (the best value is bold).
Additionally, we show the p-value of the DM-test, testing against Naive. The cells are colored with respect to their values (the greener better).




We extend the B-Smooth and P-Smooth procedures to the multivariate setting:
Let \(\boldsymbol{\psi}^{\text{mv}}=(\psi_1,\ldots, \psi_{D})\) and \(\boldsymbol{\psi}^{\text{pr}}=(\psi_1,\ldots, \psi_{P})\) be two sets of bounded basis functions on \((0,1)\):
\[\begin{equation*} \boldsymbol w_{t,k} = \boldsymbol{\psi}^{\text{mv}} \boldsymbol{b}_{t,k} {\boldsymbol{\psi}^{pr}}' \end{equation*}\]
with parameter matix \(\boldsymbol b_{t,k}\). The latter is estimated to penalize \(L_2\)-smoothing which minimizes
\[\begin{align} & \| \boldsymbol{\beta}_{t,d, k}' \boldsymbol{\varphi}^{\text{pr}} - \boldsymbol b_{t, d, k}' \boldsymbol{\psi}^{\text{pr}} \|^2_2 + \lambda^{\text{pr}} \| \mathcal{D}_{q} (\boldsymbol b_{t, d, k}' \boldsymbol{\psi}^{\text{pr}}) \|^2_2 + \nonumber \\ & \| \boldsymbol{\beta}_{t, p, k}' \boldsymbol{\varphi}^{\text{mv}} - \boldsymbol b_{t, p, k}' \boldsymbol{\psi}^{\text{mv}} \|^2_2 + \lambda^{\text{mv}} \| \mathcal{D}_{q} (\boldsymbol b_{t, p, k}' \boldsymbol{\psi}^{\text{mv}}) \|^2_2 \nonumber \end{align}\]
with differential operator \(\mathcal{D}_q\) of order \(q\)
We have an analytical solution.
Linear combinations of bounded basis functions:
\[\begin{equation} \underbrace{\boldsymbol w_{t,k}}_{D \text{ x } P} = \sum_{j=1}^{\widetilde D} \sum_{l=1}^{\widetilde P} \beta_{t,j,l,k} \varphi^{\text{mv}}_{j} \varphi^{\text{pr}}_{l} = \underbrace{\boldsymbol \varphi^{\text{mv}}}_{D\text{ x }\widetilde D} \boldsymbol \beta_{t,k} \underbrace{{\boldsymbol\varphi^{\text{pr}}}'}_{\widetilde P \text{ x }P} \nonumber \end{equation}\]
A popular choice: B-Splines
\(\boldsymbol \beta_{t,k}\) is calculated using a reduced regret matrix:
\(\underbrace{\boldsymbol r_{t,k}}_{\widetilde P \times \widetilde D} = \boldsymbol \varphi^{\text{pr}} \underbrace{\left({\boldsymbol{QL}}_{\mathcal{P}}^{\nabla}(\widetilde{\boldsymbol X}_{t},Y_t)- {\boldsymbol{QL}}_{\mathcal{P}}^{\nabla}(\widehat{\boldsymbol X}_{t},Y_t)\right)}_{\text{PxD}}\boldsymbol \varphi^{\text{mv}}\)
If \(\widetilde P = P\) it holds that \(\boldsymbol \varphi^{pr} = \boldsymbol{I}\) (pointwise)
For \(\widetilde P = 1\) we receive constant weights

| JSU1 | JSU2 | JSU3 | JSU4 | Norm1 | Norm2 | Norm3 | Norm4 | Naive |
|---|---|---|---|---|---|---|---|---|
| 1.487 | 1.444 | 1.499 | 1.374 | 1.414 | 1.535 | 1.420 | 1.422 | 1.295 |
| Description | Parameter Tuning | BOA | ML-Poly | EWA |
|---|---|---|---|---|
| Constant | 1.2933 | 1.2966 | 1.3188 | |
| Pointwise | 1.2936 | 1.3010 | 1.3101 | |
| FTL | 1.3752 | 1.3692 | 1.3863 | |
| B Constant Pr | 1.2936 | 1.3000 | 1.3432 | |
| B Constant Mv | 1.2918 | 1.2945 | 1.3076 | |
| Forget | Bayesian Fix | 1.2930 | 1.2956 | 1.3096 |
| Full | Bayesian Fix | 1.2905 | 1.2902 | 1.2870. |
| Smooth.forget | Bayesian Fix | 1.2911 | 1.2912 | 1.2869. |
| Smooth | Bayesian Fix | 1.2918 | 1.2917 | 1.2873. |
| Forget | Bayesian Online | 1.2855** | 1.2961 | 1.3098 |
| Full | Bayesian Online | 1.2919 | 1.2873. | 1.2873. |
| Smooth.forget | Bayesian Online | 1.2845** | 1.2862* | 1.2864. |
| Smooth | Bayesian Online | 1.2918 | 1.2918 | 1.2874. |
| Forget | Sampling Online | 1.2855** | 1.2961 | 1.3114 |
| Full | Sampling Online | 1.2886 | 1.2861* | 1.2873. |
| Smooth.forget | Sampling Online | 1.2845*** | 1.2867* | 1.2866. |
| Smooth | Sampling Online | 1.2918 | 1.2917 | 1.2877. |
Non-central beta distribution Johnson et al. (1995):
\[\begin{equation*} \mathcal{B}(x, a, b, c) = \sum_{j=0}^{\infty} e^{-c/2} \frac{\left( \frac{c}{2} \right)^j}{j!} I_x \left( a + j , b \right) \end{equation*}\]

Penalty and \(\lambda\) need to be adjusted accordingly Li & Cao (2022)
Using non equidistant knots in profoc is straightforward:
Basis specification b_smooth_pr is internally passed to make_basis_mats().
Profoc adjusts penatly and \(\lambda\)
Relative improvement in ES compared to \(\text{RW}^{\sigma, \rho}\)
Cellcolor: w.r.t. test statistic of Diebold-Mariano test (testing wether the model outperformes the benchmark, greener = better).
| Model | \(\text{ES}^{\text{All}}_{1-30}\) | \(\text{ES}^{\text{EUA}}_{1-30}\) | \(\text{ES}^{\text{Oil}}_{1-30}\) | \(\text{ES}^{\text{NGas}}_{1-30}\) | \(\text{ES}^{\text{Coal}}_{1-30}\) | \(\text{ES}^{\text{All}}_{1}\) | \(\text{ES}^{\text{All}}_{5}\) | \(\text{ES}^{\text{All}}_{30}\) |
|---|---|---|---|---|---|---|---|---|
| \(\textrm{RW}^{\sigma, \rho}_{}\) | 161.96 | 10.06 | 37.94 | 146.73 | 13.22 | 5.56 | 13.28 | 34.29 |
| \(\textrm{RW}^{\sigma_t, \rho_t}_{}\) | 9.40 | 3.75 | -0.41 | 11.39 | 4.13 | 10.34 | 9.10 | 7.59 |
| \(\textrm{RW}^{\sigma, \rho_t}_{\textrm{ncp}, \textrm{log}}\) | 12.04 | 6.16 | -0.56 | 14.33 | 7.35 | 9.22 | 9.82 | 10.02 |
| \(\textrm{RW}^{\sigma, \rho}_{\textrm{log}}\) | 12.10 | 6.25 | -0.59 | 14.44 | 7.31 | 9.04 | 9.66 | 9.91 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma_t, \rho_t}_{\textrm{lev}, \textrm{ncp}}\) | 9.68 | -0.72 | 0.32 | 11.74 | 3.70 | 10.82 | 10.50 | 8.21 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma, \rho_t}_{\textrm{log}}\) | 12.15 | 6.10 | -0.70 | 14.57 | 7.80 | 8.05 | 9.99 | 10.04 |
| \(\textrm{ETS}^{\sigma}\) | 9.94 | 5.75 | 0.08 | 13.05 | 7.83 | 6.96 | 7.74 | 6.21 |
| \(\textrm{ETS}^{\sigma}_{\textrm{log}}\) | 8.12 | 7.80 | -0.51 | 11.17 | 8.54 | 5.05 | 6.14 | 2.66 |
| \(\textrm{VES}^{\sigma}\) | 5.50 | -4.43 | -3.22 | 6.29 | 4.68 | -25.99 | -2.42 | 3.07 |
| \(\textrm{VES}^{\sigma}_{\textrm{log}}\) | 7.68 | 3.31 | -4.34 | 9.07 | 8.30 | -22.11 | 1.07 | 4.32 |
Improvement in CRPS of selected models relative to \(\textrm{RW}^{\sigma, \rho}_{}\) in % (higher = better). Colored according to the test statistic of a DM-Test comparing to \(\textrm{RW}^{\sigma, \rho}_{}\) (greener means lower test statistic i.e., better performance compared to \(\textrm{RW}^{\sigma, \rho}_{}\)).
EUA
|
Oil
|
NGas
|
Coal
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | H1 | H5 | H30 | H1 | H5 | H30 | H1 | H5 | H30 | H1 | H5 | H30 |
| \(\textrm{RW}^{\sigma, \rho}_{}\) | 0.4 | 0.9 | 2.1 | 1.5 | 3.4 | 9.1 | 4.7 | 11.6 | 29.8 | 0.3 | 0.9 | 2.8 |
| \(\textrm{RW}^{\sigma_t, \rho_t}_{}\) | 5.6 | 6.0 | 2.8 | 2.1 | 2.7 | -0.8 | 12.6 | 10.5 | 9.6 | 10.7 | 6.5 | 2.1 |
| \(\textrm{RW}^{\sigma, \rho_t}_{\textrm{ncp}, \textrm{log}}\) | 5.1 | 8.7 | 5.0 | 0.7 | 0.8 | -0.4 | 11.4 | 11.5 | 12.4 | 8.0 | 7.3 | 6.7 |
| \(\textrm{RW}^{\sigma, \rho}_{\textrm{log}}\) | 4.7 | 8.9 | 5.2 | 0.0 | 0.3 | -0.6 | 11.2 | 11.4 | 12.4 | 7.7 | 7.5 | 6.6 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma_t, \rho_t}_{\textrm{lev}, \textrm{ncp}}\) | 3.6 | 0.6 | -1.6 | 2.7 | 3.0 | 0.0 | 13.1 | 12.2 | 10.4 | 11.8 | 7.2 | 1.5 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma, \rho_t}_{\textrm{log}}\) | 4.2 | 8.9 | 5.1 | 0.2 | 0.4 | -0.8 | 9.9 | 11.8 | 12.7 | 7.8 | 7.9 | 7.3 |
| \(\textrm{ETS}^{\sigma}\) | 0.2 | 6.8 | 5.7 | 1.1 | 0.9 | -0.2 | 10.9 | 11.3 | 10.9 | 7.5 | 6.7 | 5.6 |
| \(\textrm{ETS}^{\sigma}_{\textrm{log}}\) | 1.0 | 8.6 | 8.0 | 0.1 | 0.7 | -0.6 | 8.9 | 9.4 | 7.1 | 7.3 | 7.8 | 6.7 |
| \(\textrm{VES}^{\sigma}\) | -38.5 | -6.4 | -5.4 | -33.3 | -6.1 | -2.4 | -26.6 | -2.6 | 3.6 | -37.5 | -5.5 | 4.7 |
| \(\textrm{VES}^{\sigma}_{\textrm{log}}\) | -32.4 | 2.8 | 1.8 | -30.4 | -6.2 | -3.2 | -22.0 | 1.8 | 5.4 | -27.0 | 2.3 | 6.4 |
RMSE measures the performance of the forecasts at their mean
Conclusion: the Improvements seen before must be attributed to other parts of the multivariate probabilistic predictive distribution
Improvement in RMSE score of selected models relative to \(\textrm{RW}^{\sigma, \rho}_{}\) in % (higher = better). Colored according to the test statistic of a DM-Test comparing to \(\textrm{RW}^{\sigma, \rho}_{}\) (greener means lower test statistic i.e., better performance compared to \(\textrm{RW}^{\sigma, \rho}_{}\)).
EUA
|
Oil
|
NGas
|
Coal
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | H1 | H5 | H30 | H1 | H5 | H30 | H1 | H5 | H30 | H1 | H5 | H30 |
| \(\textrm{RW}^{\sigma, \rho}_{}\) | 0.9 | 2.0 | 5.0 | 2.9 | 6.4 | 16.7 | 17.8 | 42.8 | 85.4 | 0.9 | 2.9 | 7.0 |
| \(\textrm{RW}^{\sigma_t, \rho_t}_{}\) | -0.1 | -0.1 | 0.7 | 0.0 | -0.3 | -0.1 | -0.2 | 0.3 | 1.3 | -0.2 | 0.0 | -1.8 |
| \(\textrm{RW}^{\sigma, \rho_t}_{\textrm{ncp}, \textrm{log}}\) | -270.5 | -154.1 | -139.9 | 0.5 | -0.5 | -2.9 | -0.8 | 0.7 | -1.6 | 0.3 | -31.2 | -24.5 |
| \(\textrm{RW}^{\sigma, \rho}_{\textrm{log}}\) | -705.0 | -265.4 | -125.2 | 0.6 | 0.2 | -0.2 | -0.4 | 0.1 | -1.6 | -0.9 | -0.3 | -8.3 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma_t, \rho_t}_{\textrm{lev}, \textrm{ncp}}\) | -0.9 | 0.2 | 0.5 | 0.5 | 0.2 | 0.0 | -0.4 | 0.7 | 0.2 | 1.4 | 0.1 | 0.2 |
| \(\textrm{VECM}^{\textrm{r0}, \sigma, \rho_t}_{\textrm{log}}\) | -271.5 | -191.3 | -114.3 | 1.7 | -12.3 | -3.6 | -0.6 | 1.6 | -4.1 | 0.0 | -0.8 | -6.7 |
| \(\textrm{ETS}^{\sigma}\) | -0.3 | 0.3 | 1.6 | 0.7 | 0.1 | -0.1 | 0.1 | -0.1 | 0.2 | -2.4 | -3.9 | 2.5 |
| \(\textrm{ETS}^{\sigma}_{\textrm{log}}\) | -1.0 | 0.4 | 1.6 | 0.9 | 0.0 | -0.1 | -1.9 | -1.9 | -13.9 | -0.3 | -3.6 | -1.8 |
| \(\textrm{VES}^{\sigma}\) | -37.4 | -8.9 | -6.0 | -27.9 | -7.4 | -2.8 | -27.2 | -9.5 | -2.4 | -41.7 | -1.2 | 1.6 |
| \(\textrm{VES}^{\sigma}_{\textrm{log}}\) | -37.6 | -9.2 | -7.8 | -26.8 | -7.3 | -3.0 | -27.0 | -6.8 | -3.5 | -41.2 | -2.2 | -0.3 |


Accounting for heteroscedasticity or stabilizing the variance via log transformation is crucial for good performance in terms of ES













